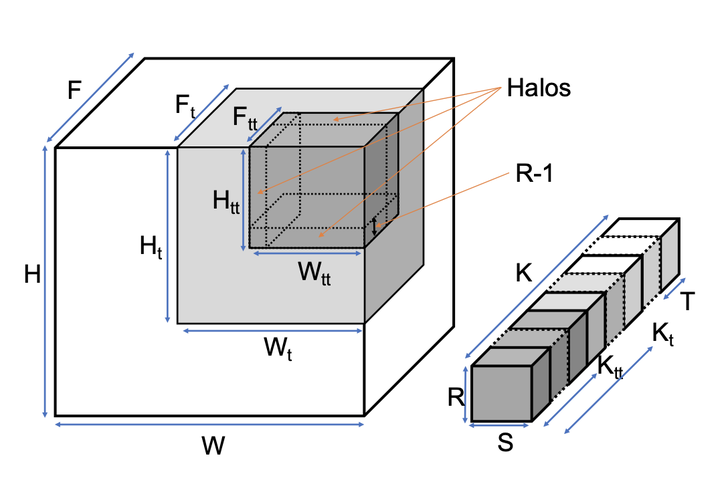
 Tiled 3D-Convolution
Tiled 3D-ConvolutionAbstract
The past several years have seen both an explosion in the use of Convolutional Neural Networks (CNNs) and the design of accelerators to make CNN inference practical. In the architecture community, the lion share of effort has targeted CNN inference for image recognition. The closely related problem of video recognition has received far less attention as an accelerator target. This is surprising, as video recognition is more compu- tationally intensive than image recognition, and video traffic is predicted to be the majority of internet traffic in the coming years. This paper fills the gap between algorithmic and hardware advances for video recognition by providing a design space explo- ration and flexible architecture for accelerating 3D Convolutional Neural Networks (3D CNNs)—the core kernel in modern video understanding. When compared to (2D) CNNs used for image recognition, efficiently accelerating 3D CNNs poses a significant engineering challenge due to their large (and variable over time) memory footprint and higher dimensionality
Kartik Hegde
Founder and CEO at ChipStack
My research interests are in developing high-performance domain-specific programmable processors for modern data centres and cloud computing.