 Varying Sparsity in Different Areas of Computing
Varying Sparsity in Different Areas of ComputingAbstract
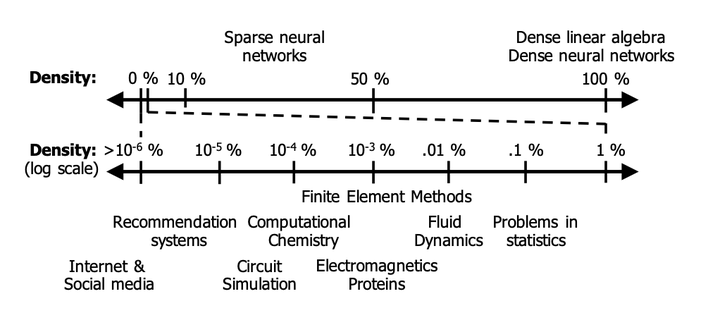
Generalized tensor algebra is a prime candidate for acceleration via customized ASICs. Modern tensors feature a wide range of data sparsity, with the density of non-zero elements ranging from 10−6% to 50%. This paper proposes a novel approach to accelerate tensor kernels based on the principle of hierarchical elimination of com- putation in the presence of sparsity. This approach relies on rapidly inding intersectionsÐsituations where both operands of a multipli- cation are non-zeroÐenabling new data fetching mechanisms and avoiding memory latency overheads associated with sparse kernels implemented in software. We propose the ExTensor accelerator, which builds these novel ideas on handling sparsity into hardware to enable better band- width utilization and compute throughput. We evaluate ExTensor on several kernels relative to industry libraries (Intel MKL) and state-of-the-art tensor algebra compilers (TACO). When bandwidth normalized, we demonstrate an average speedup of 3.4×, 1.3×, 2.8×, 24.9×, and 2.7× on SpMSpM, SpMM, TTV, TTM, and SDDMM ker- nels respectively over a server class CPU.
Kartik Hegde
Founder and CEO at ChipStack
My research interests are in developing high-performance domain-specific programmable processors for modern data centres and cloud computing.