Buffets: An Efficient and Composable Storage Idiom for Explicit Decoupled Data Orchestration
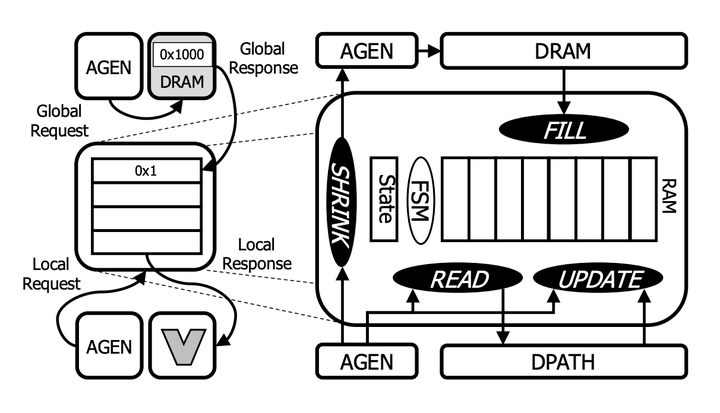 Buffet Storage Idiom
Buffet Storage IdiomAbstract
Accelerators spend significant area and effort on custom onchip buffering. Unfortunately, these solutions are strongly tied to particular designs, hampering re-usability across other accelerators or domains. We present buffets, an efficient and composable storage idiom for the needs of accelerators that is independent of any particular design. Buffets have several distinguishing characteristics, including efficient decoupled fills and accesses with fine-grained synchronization, hierarchical composition, and efficient multi-casting. We implement buffets in RTL and show that they only add 2% control overhead over an 8KB RAM. When compared with DMAmanaged double-buffered scratchpads and caches across a range of workloads, buffets improve energy-delay-product by 1.53× and 5.39×, respectively.
Kartik Hegde
Founder and CEO at ChipStack
My research interests are in developing high-performance domain-specific programmable processors for modern data centres and cloud computing.